Table of Contents
Introduction to Pipelining
Image processing in MITK draws heavily from the pipelining concept, and a clear understaning of it is crucial when developing with MITK. This document will first clarify the general idea behind pipelining and then discuss some MITK specifics that you should know about.
In the real world, a pipeline connects a source of some kind with a consumer of another. So we identify three key concepts:
- The source, which generates data of some kind.
- The pipeline, which transports the data. Many different pipeline segments can be switched in line to achieve this.
- The consumer, which uses the data to do something of interest.
The analogy to real pipelines falls a little short in one point: A physical pipeline would never process it's contents, while in software development a pipeline usually does (this is why they are often dubbed filters as well). One might ask why one shouldn't just implement the processing logic in the consumer onject itself, since it onviously knows best what to do with it's data. The two main reasons for this are reusability and flexibility. Say, one wants to display a bone segmentation from a CT-image. Let's also assume for the sake of this introduction, that this is a simple task. One could build a monolithic class that solves the problem. Or one builds a pipeline between the displaying class and the source. We know that bones are very bright in a CT Scan, so we use a threshold filter, and then a segmentation Filter to solve the problem.

Now let's further assume that after successfully selling this new technology to a large firm, we plan to do the same with ultrasound imaging technology. The brithness relations in Ultrasound images are basically the same, but ultrasound images are very noisy, and the contrast is significantly lower. Since we used pipelining, this is no problem: We don't need to change our old segmentation class - we just plug two new filters in front of the pipeline:

This may seem trivial, but when working with several input streams from many different devices that themselves stem from many different vendors, pipelining can save the day when it comes to broad range support of different specifications.
Pipelining in MITK
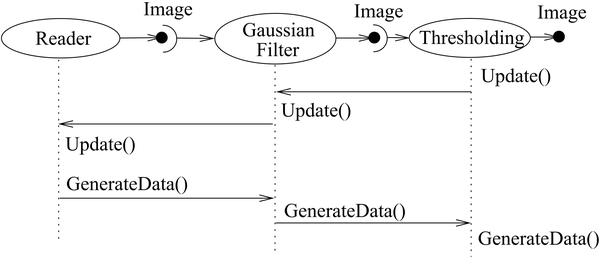
The Update() Mechanism
The flow of data inside a pipeline is triggered by only one function call to the consumer, which is Update(). Each part of the pipeline then triggers the Update() method of it's antecessor. Finally, the source creates a new batch of data using it's own GenerateData() method, and notifies its successor that new data is available. The pipeline can then start to process the data until the finished data batch is available as an output of the last Filter.
The Pipeline Hierarchy
The base class for all parts of the pipeline except the consumer (which can be of any class) is mitk::Baseprocess. This class introduces the ability to process data, has an output and may have an input as well. You will however rarly work with this class directly.
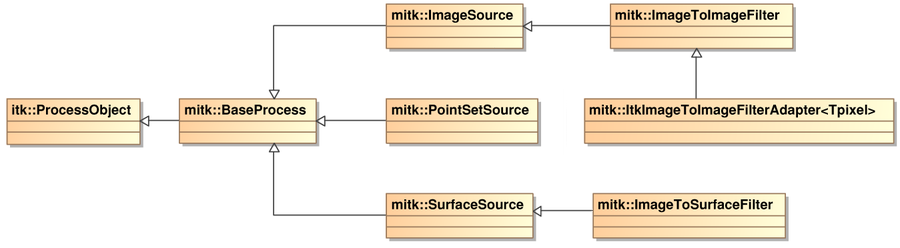
Several source classes extend BaseProcess. Depending on the type of data they deliver, these are ImageSource, PointSetSource and SurfaceSource. All of these mark the start of a pipeline.
The filters themselves extend one of the source classes. This may not immediately make sense, but remember that a filter basically is a source with an additional input.
Working with Filter
Setting Up a Pipeline
// Create Participants
mitk::USVideoDevice::Pointer videoDevice = mitk::USVideoDevice::New("-1", "Manufacturer", "Model");
TestUSFilter::Pointer filter = TestUSFilter::New();
// Make Videodevice produce it's first set of Data, so it's output isn't empty
videoDevice->Update();
// attach filter input to device output
filter->SetInput(videoDevice->GetOutput());
// Pipeline is now functional
filter->Update();
Writing Your Own Filter
When writing your first Filter, this is the recommended way to go about:
- Identify which kinds of Data you require for input, and which for output
- According to the information from step one, extend the most specific subclass of BaseProcess available. E.g. a filter that processes images, should extend ImageToImageFilter.
- Identify how many inputs and how many outputs you require.
- In the constructor, define the number of outputs, and create an output.
//set number of outputs this->SetNumberOfOutputs(1); //create a new output mitk::Image::Pointer newOutput = mitk::Image::New(); this->SetNthOutput(0, newOutput);
- Implement MakeOutput(). This Method creates a new, clean Output that can be written to. Refer to Filters with similar task for this.
- Implement GenerateData(). This Method will generate the output based on the input it. At time of execution you can assume that the Data in input is a new set.
